در حال حاضر خالی است: ریال0


هدف مقاله
همانطور که پستپروسسورها و مهندسی آنالیز داده در جریان هستند بعضی از مواقع حجم سمپل های مورد نظر به میزان غیر قابل تصوری بالاست و برای نمایش آن در وب و یا حتی در نقشه های لوکال به مشکل میخورند به جهت سبک سازی دیتاهای اینچنینی اخیرا از راه حلی استفاده کردم که آسیبی به ساختار سمپلها نمیزند ولی حجم سمپلها را به شکل قابل توجهی کاهش میدهد.
خوشه بندی
خوشه بندی یا کلاسه کردن دیتاها از روشهایی هست که در علم داده به مراتب استفاده می شود و در جهت ساده سازی دادهها از نظر شباهت استفاده میگردد به شکلی که در نتیجه تغییر محسوسی ایجاد نشود.
خوشه بندی دیتای شبکه GSM با استفاده از پایتون
برای انجام این کار از خروجی تست شبکه GSM استفاده کردم که شامل فیلدهای زمان،مکان،CellID و RxLevel میباشد، که به شکل زیر روند کلاسهسازی دادهها را مشخص نمودم:
- جداسازی سمپلها در بازههای پنج تایی
- ایجاد محدودیت زمانی برای هر کلاستر(زیر 20 ثانیه)
- ایجاد محدودیت عددی در هر کلاستر(زیر پنح سمپل)
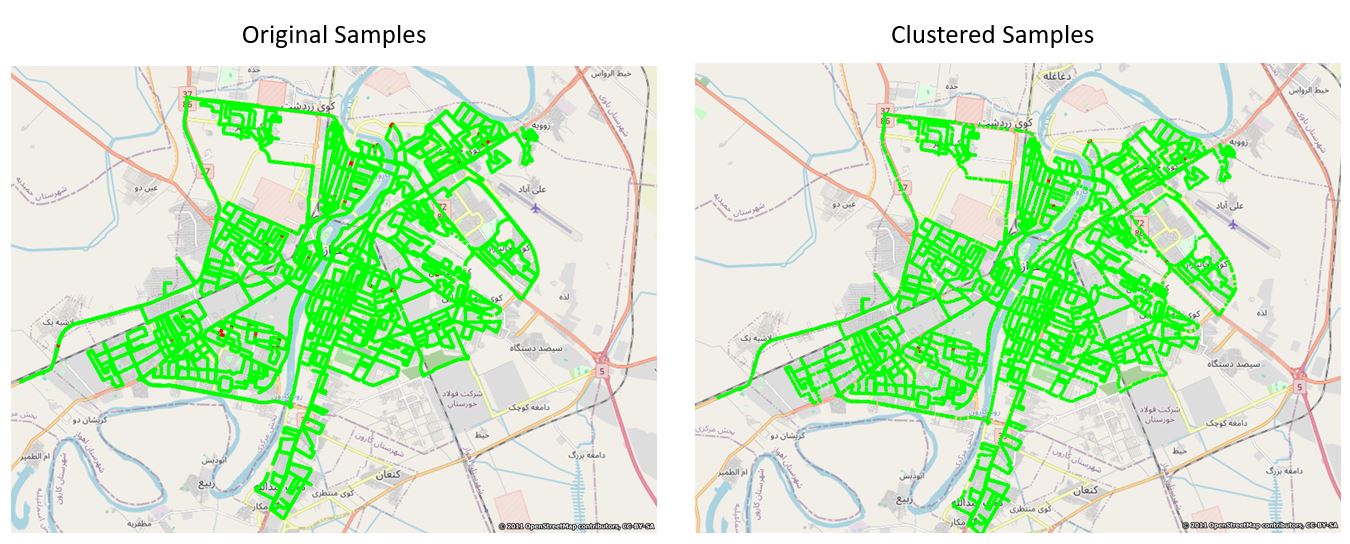
در این مقاله از سمپلهای سیگنالهای شبکه GSM استفاده کردم که با استفاده از روش فوق تعداد سمپلها را از 78210 به 19390 سمپل رسانیدم که در ذیل پلاتهای هرکدام را به صورت جداگانه میتوانید مشاهده کنید و همچنین کد نوشه شده در پایان مقاله قرار داده شده است.


def date_diff_in_Seconds(dt1, dt2):
# Calculate the time difference between dt2 and dt1
# Step 2: Extract milliseconds separately and add them to the parsed datetime object
timedelta = datetime.strptime(dt2[:-4], '%m/%d/%Y %H:%M:%S') - datetime.strptime(dt1[:-4], '%m/%d/%Y %H:%M:%S')
# Return the total time difference in seconds
return timedelta.days * 24 * 3600 + timedelta.seconds
ef get_2GLocked_IDLE_cluster_fromExcel():
KPI_gsm = pd.read_excel("Original.xlsx", sheet_name='GSM_KPI')
lstGSMRanges = []
base = -150
offset = 5
cluster_samples = 10
cluster_Time = 20
min = base
max = base + 5
while min < 0:
crange = KPI_gsm.query("`RxLevel` >= @min and `RxLevel` < @max")
if len(crange.index) >0:
lstGSMRanges.append(crange)
min = max
max += 5
clusters = pd.DataFrame(columns=['DateTime', 'Latitude', 'Longitude','CellID','RxLevel'])
c_cluster = pd.DataFrame(columns=['DateTime', 'Latitude', 'Longitude','CellID','RxLevel'])
cluster_time=10
for gsmrange in lstGSMRanges:
for index, row in gsmrange.iterrows():
c_cluster=c_cluster.append({'DateTime':row['Date Time'],'Latitude':row['Latitude'],'Longitude':row['Longitude'],'CellID':row['Cell-ID'],'RxLevel':row['RxLevel']}, ignore_index=True)
if len(c_cluster.index) > 1:
if postfunc.date_diff_in_Seconds(c_cluster.iloc[0]['DateTime'],c_cluster.iloc[len(c_cluster.index)-1]['DateTime']) >= cluster_time or len(c_cluster.index)==5:
clusters = clusters.append({'DateTime':c_cluster.loc[0]['DateTime'],'Latitude':c_cluster.loc[0]['Latitude'],'Longitude':c_cluster.loc[0]['Longitude'],'CellID':c_cluster.loc[0]['CellID'],'RxLevel':c_cluster['RxLevel'].mean()}, ignore_index=True)
c_cluster = c_cluster.iloc[0:0]
clusters.to_csv('clusters.csv', index=False)

پیمان هوشمند
سلام امیدوارم حال همگی شما خوب باشه.من پیمان هوشمند هستم. مدرس برنامه نویسی و نرم افزارهای تحلیلی در حوزه مخابرات. خود من همیشه به عنوان یه دانش آموزش و دانش پژوه عاشق برنامه نویسی و کارهای آماری بودم و نقطه قوتم حتی در زمان تحصیل خودم هم مباحث برنامه نویسی بخصوص طراحی الگوریتم بوده. بنابراین این درس را خیلی مفهومی و عمیق یاد گرفتم. تفاوت عمیق من با دانشجویان در زمان تحصیلم این بود که در حوزه ای که تحصیل میکردم مشغول به کار بودم و این دلیل بر عمیق تر شدن در حوزه نرم افزار و مخابرات بود و از دانشگاه برای فهم بیشتر مبانی های کارم استفاده کردم. تا به امروز در اکثر سازمانهایی که کار کرده ام در کنار سمت اصلیم ، به عنوان سوپروایزر آموزشی هم فعالیت میکردم و متخصصینی در این حوزه آموزش داده ام و در بازار کار مشغول به کار هستند و در مدتی که کرونا باعث تعطیلی بسیاری از مراکز آموزش بود ، به صورت رایگان در خدمت دانشجویان نرم افزار از دانشگاه های مختلف بودم. همیشه در روش های آموزشیم بدنبال ابتکار و نوآوری هایی از قبیل گیمیفیکیشن و تکنیک های شناختی به جهت بهبود یادگیری بوده ام.